Streaming User Events from PostgreSQL (Supabase) to Serverless Kafka

Kafka Connectors are components that can be used for importing data from external data stores to Kafka topics and exporting data from Kafka topics to external systems.
Kafka Connectors can help data stores to be streamed through Kafka topics once data updated. Thanks to this, any data updates can be consumed by different services by subscribing to Kafka topics.
In the first part of this blog post, we are going to mimic backend of a social media application by storing user activities, such as likes and comments, on Postgres tables in Supabase. Afterwards, we are going to stream these user activities from Postgres tables to Upstash Kafka through Kafka Connectors.
In the second part, we are going to utilize that streamed data by creating a leaderboard on Upstash Redis as an example.
Here is the flow of the user data for better visualization.
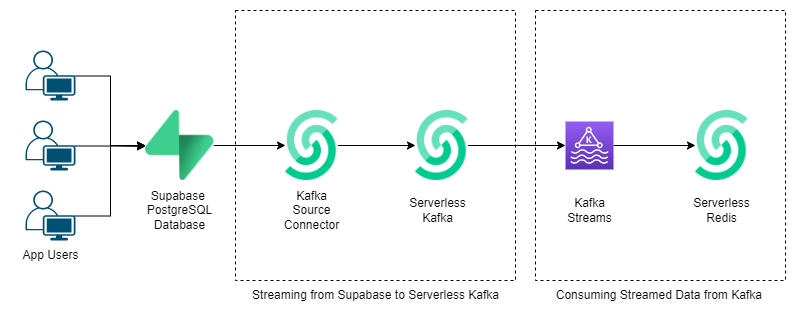
What is Supabase?
Supabase is an open-source alternative of Firebase. They aim to provide services like Firebase with different technological choices. Main differences that distinguish Supabase from Firebase:
- Everything they use is open-source
- Support existing tools rather than building from scratch
- Providing PostgreSQL rather than NoSQL
Currently, Supabase provides following services:
- Authentication
- Database (PostgreSQL)
- Storage
- Edge Functions
Detailed information about Supabase can be found on Supabase website.
Upstash Kafka Setup
First, we need to login Upstash console and navigate to Kafka.
We need to create a Kafka cluster by following Upstash Kafka Docs.
There is no need to create any topic for now. Once we have a Kafka cluster, we can continue with Supabase.
Supabase Setup
First of all, we need to sign in and create new project.
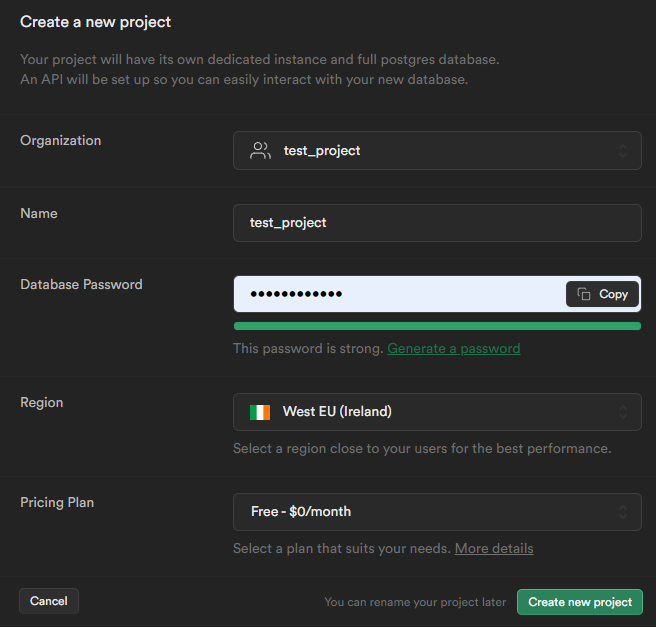
While creating project, don’t lose the database password. It will be used while creating Serverless Kafka Connector.
After the project created, we can navigate to database tab on right bar and create tables. It is very easy to create tables with one click.
The first will store comments that users have written on posts. Second one will store likes of the users. For that purpose, the first table we are going to create is Comments table with comment id, user id, post id, comment columns.
We need to enable realtime while creating the table. We can configure column settings. For example, in this post, we are going to set comment_id as primary, comment column nullable.

Second table will be likes table with user id, post id. We again need to enable realtime and for this case, we are going to set user_id as primary.
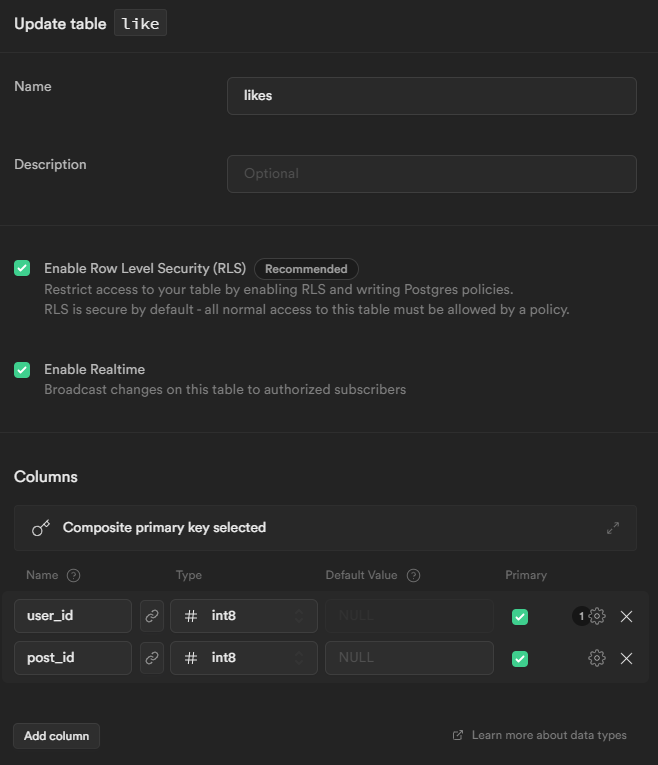
Our database for user activities are ready!
We can add rows to the tables by going table editor in right bar.
Let’s assume a user both liked and commented on a post.
For comments table, we can add the first example row:
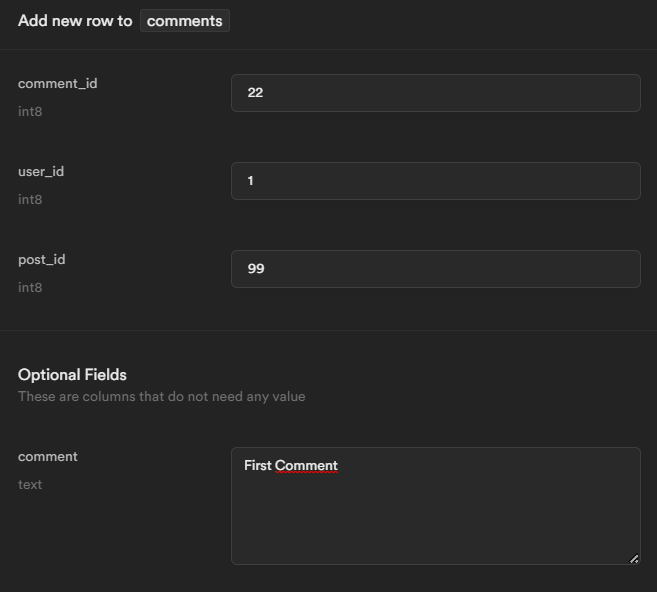
For likes table:

It is very easy, isn’t it?
Creating Upstash Kafka Connector
Before creating connector, we need to set “postgres” user as Super User, since Debezium needs that for our use case.
To do this, we need to go to the SQL Editor in right bar and create new query. In this tool, we need to run following command:
ALTER USER postgres WITH SUPERUSER;After running this, we should see the output:
“Success. No rows returned.”
Now, we need to go back to Upstash console and open connectors tab in our kafka cluster.
When we click to new connector button, we can see connector options. We will select Debezium Source PostgreSQL Connector since Supabase is PostgreSQL database.
To fill out the config step for new connector, we need to go back to our Supabase project and open database settings from right tab bar. We are going to use host, port, user, password (password of the project), database name in config step.
You can fill connector name and server name as you wish.
For the rest, we will define which schema and tables we are going to stream from. For our case, schema will be public, tables will be public.Comments,public.Likes.

In the last step, we can review Debezium connector settings as JSON. At this step, we should add 2 new property to prevent failures:
"plugin.name": "pgoutput",
"publication.autocreate.mode": "filtered"Now, we should be able to run this Kafka connector. Currently, connector config looks like following:
{
"name": "MyConnector",
"properties": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "db.acoyeduxnqeaurrjgaox.supabase.co",
"database.port": "5432",
"database.user": "postgres",
"database.password": "********",
"database.dbname": "postgres",
"database.server.name": "user",
"schema.include.list": "public",
"plugin.name": "pgoutput",
"publication.autocreate.mode": "filtered",
"table.include.list": "public.comments,public.likes",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": true,
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": true
}
}Once created the connector, we will see that topics named public.comments and public.likes created automatically.
Stream Data from Supabase to Kafka
Let’s test our connector!
Open new created topics in separate tabs and navigate to messages section to observe new coming messages.
To see incoming messages, we need to populate Supabase tables. Go back to Supabase table editor and insert rows to the tables, as we did previously in this blog.
After we add new row, then we can observe the corresponding topic. Example incoming message:

Consuming Streamed Data from Kafka
Up until now, we streamed likes and comments of users from Supabase PostgreSQL to Serverless Kafka.
Now, we are going to implement an example application to see how these streams can be consumed and used.
We can create a leaderboard!
All users are going to have scores according to their activities. They will earn 2 points for every “comment” they provided and 1 point for every “like” activity.
To store this leaderboard, we can use sorted sets in Serverless Redis. To create Redis, please follow the steps in Serverless Redis Docs.
Let’s create a Java application to stream data from Kafka topics via Kafka Streams. Then we can use the data to increment scores of the users in leaderboard we store in Redis.
First, we should add dependencies we are going to use.
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.14.2</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.4.0</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>4.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>3.3.1</version>
</dependency>Then, we should connect to our Serverless Redis.
Jedis jedis = new Jedis("UPSTASH-REDIS-ENDPOINT", 38900);
jedis.auth("UPSTASH-REDIS-PASSWORD");Once we create Redis connection, we can configure Kafka Streams.
Properties props = new Properties();
props.put(StreamsConfig._BOOTSTRAP_SERVERS_CONFIG_, "UPSTASH-KAFKA-ENDPOINT:9092");
props.put(SaslConfigs._SASL_MECHANISM_, "SCRAM-SHA-256");
props.put(StreamsConfig._SECURITY_PROTOCOL_CONFIG_, "SASL_SSL");
props.put(StreamsConfig._APPLICATION_ID_CONFIG_,"leaderboard-app");
props.put("auto.offset.reset", "latest");
props.put(SaslConfigs._SASL_JAAS_CONFIG_, "org.apache.kafka.common.security.scram.ScramLoginModule required username=\"UPSTASH-KAFKA-USERNAME\" password=\"UPSTASH-KAFKA-PASSWORD\";");
props.put(StreamsConfig._DEFAULT_KEY_SERDE_CLASS_CONFIG_, Serdes._String_().getClass());
props.put(StreamsConfig._DEFAULT_VALUE_SERDE_CLASS_CONFIG_, Serdes._String_().getClass());We should create a Kafka Streams builder to specify the topics we are going to stream from. To do this, we will use the prefix of the Kafka topics created by Kafka Connector.
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> source = builder.stream(Pattern._compile_("user.public.*"));Now, it is time to implement what we are going to do with the data we streamed.
We are going to use JsonNodes to retrieve the fields from Kafka messages. To increase the scores in leaderboard, we will use ZINCRBY method.
source.foreach((key, value) -> {
try {
final ObjectMapper mapper = new ObjectMapper();
JsonNode actualObj = mapper.readTree(value);
String table = actualObj.get("payload").get("source").get("table").asText();
JsonNode row = actualObj.get("payload").get("after");
if(table.equals("likes")){
jedis.zincrby("Leaderboard", 1, row.get("user_id").asText());
System._out_.println("like row: " + row);
}
else if(table.equals("comments")){
jedis.zincrby("Leaderboard", 2, row.get("user_id").asText());
System._out_.println("comment row: " + row);
}
} catch (JsonProcessingException e) {
e.printStackTrace();
}
});Finally, we can start streaming!
final Topology topology = builder.build();
System._out_.println(topology.describe());
final KafkaStreams streams = new KafkaStreams(topology, props);
final CountDownLatch latch = new CountDownLatch(1);
try {
streams.start();
System._out_.println("streams started");
latch.await();
} catch (final Throwable e) {
System._exit_(1);
}
Runtime._getRuntime_().addShutdownHook(new Thread("streams-word-count") {
@Override
public void run() {
streams.close();
latch.countDown();
}
});For testing, once we add new rows to Supabase tables, we can observe the increase in the Leaderboard by running command below in Upstash Redis CLI.
ZRANGE Leaderboard 0 -1 WITHSCORES
So simple, isn’t it?